Pythonのハマりどころ: そのまま使うと遅くなる理由
Pythonは遅い、とよく言われる。
しかし実際には、その多くは言語そのものの問題ではなく、「デフォルトのまま使っていること」に起因している。
Pythonは可読性や後方互換性を重視した設計であり、初期設定は必ずしもパフォーマンス最適ではない。
本記事では、実運用で見落とされがちな初期設定の罠をいくつか取り上げる。
古いバージョンを使い続ける
Pythonのバージョンは、そのまま性能に直結する。
特に3.11以降では、Faster CPythonプロジェクトにより、 バージョンごとにインタプリタレベルでの最適化が大きく進んでいる。
にもかかわらず、互換性や運用、チュートリアルやオンボーディングの都合で古いバージョンが使われ続けるケースは少なくない。
これは最も単純で、かつ影響の大きい「罠」である。
新しいバージョンが毎年10月ごろにリリースされるので確認しよう。
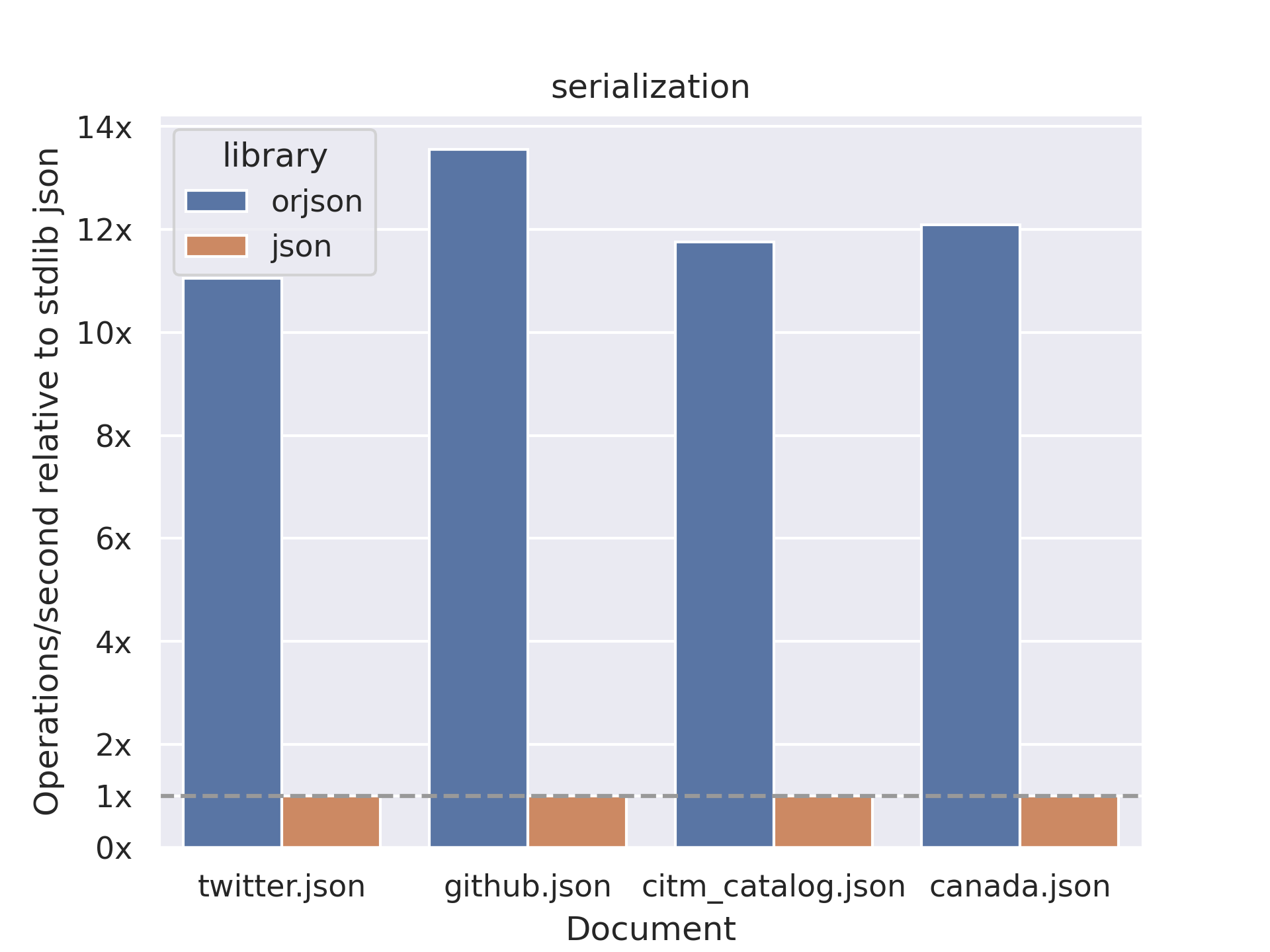
標準jsonライブラリをそのまま使う
Pythonの標準ライブラリは信頼性が高い一方で、必ずしも高速ではない。他言語では高速なJSON処理が標準で提供されることも多いが、Pythonではそうではない。
アプリケーションにせよデータ分析にせよほとんどがjsonを操作する時代、特にjsonモジュールが遅く、スピードやCPU負荷に影響しがち。orjsonやsimdjsonといった高速な実装を利用しよう。
HTTP/TCP接続を使い捨てる(boto3など)
近年の言語やフレームワークでは、接続再利用やコネクションプーリングが標準的に提供されている。ただし、その恩恵をどの程度「デフォルトで受けられるか」は、API設計や利用方法に依存する。
Pythonでは、シンプルに書いたコードが結果として接続を使い捨てる形になりやすく、明示的に設定しなければ最適な動作にならない場合がある。
例えば多くのHTTPクライアントは、特別な設定をしない限り、接続の再利用が十分に活用されない。boto3やrequestsなどでは、TCP接続のkeep-aliveやコネクションプーリングの設定が重要になる。
これらを意識しない場合、不要な接続確立が繰り返され、レイテンシとコストの両方に影響を与える。
iterableをすぐにlistに変換する
Pythonでもイテレーターをよく使う。遅延評価やストリーム処理は多くの言語で重視されているが、Pythonではlistへの変換が安易に行われがちである。
このパターンは、
- 不要なメモリ確保
- 無駄な全件評価
を引き起こす。
特にデータ量が増えたとき、顕著な性能低下につながる。 listに変換して全件処理してはiterableに戻す、といった処理を繰り返す設計は避けよう。何度も何度も全件処理してないか確認すること。
ブロッキングI/Oと同期処理に注意
Pythonのコードは簡潔に書けるが、その背後でI/O待ちが発生していることは少なくない。
同期的なAPI呼び出しをそのまま並べると、処理は逐次実行される。 さらに、多くの場合これらはブロッキングI/Oであり、待ち時間のあいだ他の処理を進めることができない。
モダンな言語では非同期処理が標準的に組み込まれていることが多いが、Pythonでは明示的に設計しなければ逐次実行になる。
I/O待ちが支配的なワークロードでは、asyncや並列処理を導入することで、スループットが大きく改善する場合がある。
uvを使おう
Pythonの開発環境は長らく分散していたが、近年はuvやruffといった高速なツールが急速に普及している。
これらは初期設定のままでも高速に動作するよう設計されており、従来のツールチェーンと比較して開発体験に差が出る。
新規プロジェクトでは必ず使おう。